Antes de tratar o assunto de 'tuning' na base de dados de uma aplicação, tentamos definir o que é 'tuning' de banco de dados. Abordamos superficialmente os principais problemas encontrados e sugerimos uma metodologia para realizar 'tuning' em aplicações. Desta metodologia nos aprofundamos um pouco mais no 'tuning' das operações na base de dados que acreditamos ser um dos problemas mais freqüentes na utilização de Sistemas Gerenciadores de Banco de Dados (SGBD).
1. Visão geral
A tradução literal de ‘tuning’ seria sintonia ou ajuste de alguma coisa para que funcione melhor. Um SGBD é um produto de software sofisticado permitindo vários ajustes. Sua flexibilidade permite você fazer pequenos ajustes que afetam a performance do banco de dados.
Porém, o que é performance de banco de dados? Para responder a esta pergunta vamos fazer uma analogia em termos de oferta e demanda. Os usuários demandam informações do banco de dados. O SGBD fornece informação para aqueles que o pedem. A taxa entre os pedidos que o SGBD atende e a demanda para informação pode ser denominado performance de banco de dados. Cinco fatores influenciam a performance do banco de dados: ‘workload’, ‘throughput’, recursos, otimização e contenção.
‘Workload’ são os pedidos do SGBD que definem a demanda. Ele é o conjunto de transações online, jobs batch, pesquisas ad hoc, etc.
‘Throughput’ define a capacidade do computador de processar os dados. Ele é uma composição de velocidade de I/O, velocidade da CPU, capacidades de paralelismo da máquina e a eficiência do sistema operacional e o software básico envolvido.
O hardware e ferramentas de software disponíveis do sistema são conhecidos como recursos do sistema.
Todos os sistemas podem ser otimizados, mas banco de dados relacionais são os únicos em que a otimização de pesquisas é primariamente realizada internamente ao SGBD.
Quando a demanda (workload) para um recurso particular é alta, pode acontecer a contenção. Contenção é a condição em que dois ou mais componentes do ‘workload’ estão tentando usar o mesmo recurso em modos conflitantes (por exemplo, duas atualizações no mesmo dado). Se a contenção cresce o ‘throughput’ diminui.
Performance de banco de dados então pode ser definida como otimização de recursos usados para aumentar ‘throughput’ e minimizar contenção, permitindo que o maior ‘workload’ possível possa ser processado.
Não importa o quanto um SGBD é complexo e cheio de características, a coisa mais problemática para os que o utilizam é a sua performance. Se houver problema de performance, o uso da aplicação declinará e as supostas vantagens competitivas disponibilizadas pela aplicação não ocorrerão. O planejamento para o gerenciamento da performance do banco de dados é um componente crucial de qualquer implementação de aplicação. Sem um plano para monitorar performance e ajustar o banco de dados, a degradação da performance fatalmente ocorrerá. Um plano completo de gerenciamento de performance incluirá ferramentas para ajudar a monitorar a performance da aplicação e o ajuste do SGBD.
Por ‘tuning’ da base de dados, poderíamos entender como uma customização do sistema sob medida para que a performance atenda melhor as suas necessidades.
2. Metodologia para Ajuste de Performance
Uma metodologia bem planejada é a chave do sucesso para realizar ‘tuning’ de performance. Para obter melhores resultados, ajuste durante a fase de projeto em vez de esperar para ajustar depois da implementação do sistema. O tempo mais efetivo para este ajuste é durante a fase de projeto: você consegue o máximo de benefício por um baixo custo.
A abordagem mais efetiva para realizar ‘tuning’ é a abordagem pró-ativa na fase de projeto. O processo de ‘tuning’ não começa quando os usuários reclamam sobre tempo de respostas ruins. Quando o tempo de resposta está ruim, geralmente é muito tarde para usar algumas das estratégias mais eficientes de ‘tuning’. Neste ponto, se você não quiser redesenhar completamente a aplicação, você pode somente melhorar a performance pela realocação de memória e ajuste de I/O. Você pode chegar à conclusão que tanto o SGBD quanto o sistema operacional estão funcionando bem. Neste caso, para conseguir obter performance adicional você precisaria ajustar a aplicação ou adicionar recursos.
Somente com um sistema bem projetado você pode obter vantagens completas das características que o SGBD fornece para melhoria de performance. Mesmo a performance de um sistema bem projetado pode degradar com o uso. Por isso, a tarefa de ‘tuning’ é uma parte importante da manutenção do sistema.
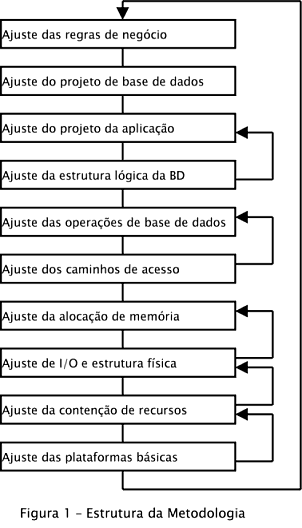
Uma metodologia recomendada para ‘tuning’ deveria seguir os seguintes passos:
A tarefa de ‘tuning’ é um processo interativo. Ganhos de performance feitos em um passo podem influenciar outros passos.
2.1 Ajuste das Regras de Negócio
Para obter a performance ideal, você pode ter que adaptar regras de negócio. Isto se refere a uma análise do sistema inteiro em mais alto nível. Deste modo, os planejadores garantem que os requisitos de performance do sistema correspondam diretamente às necessidades concretas do negócio. Problemas de performance encontrados pelo DBA podem ser causados por problemas no projeto e implementação ou regras de negócio inapropriadas. Por exemplo, a função de negócio de impressão de cheques. O requisito real é pagar dinheiro a pessoas; o requisito não é necessariamente imprimir pedaços de papel. Poderia ser bastante complicado imprimir milhares de cheques por dia. Seria relativamente mais fácil gravar os depósitos de pagamento em uma fita que seria enviada ao banco para processamento.
2.2 Ajuste do projeto de Base de Dados
Na fase de projeto de base de dados, você deve determinar que dados são necessários pelas suas aplicações. Você precisa considerar que relações são importantes e quais são seus atributos. Finalmente, você precisa estruturar a informação para melhor atingir suas metas de performance. O processo de projeto da base de dados geralmente desce ao estágio de normalização quando os dados são analisados para eliminar a redundância de dados. Com a exceção das chaves primárias, qualquer outro dado deveria ser armazenado somente uma vez na sua base.
Depois de normalizar os dados, entretanto, você pode precisar denormalizar por razões de performance. Segundo George Koch[1], nenhuma aplicação principal rodará na terceira forma normal. A aderência muito rígida para projetos de tabelas relacionais trarão performance ruim. O problema é que estes projetos refletem os modos em que os dados de uma aplicação estão relacionados com outros dados. Eles não refletem os caminhos de acessos normais que os usuários empregarão para acessar estes dados. Uma vez que as necessidades de acesso dos usuários evoluem, o projeto de tabelas relacionais se tornará difícil de trabalhar para pesquisas muito grandes. Um problema ocorrerá com pesquisas que retornam um número muito grande de colunas. Estas colunas são normalmente espalhadas entre várias tabelas, forçando a junção de tabelas durante a pesquisa. Se uma das tabelas da junção for grande, então a performance de toda a pesquisa poderá sofrer. Há várias formas de denormalização de dados, por exemplo, criando pequenas tabelas sumarizadas para tabelas grandes e estáticas. Se os usuários freqüentemente utilizam um dado derivado que não sofre muitas modificações, então faz sentido armazenar periodicamente o dado no formato em que os usuários utilizarão. Opções de projeto incluem a separação de uma tabela em múltiplas tabelas e, o contrário, combinando múltiplas tabelas em uma. A ênfase deveria ser em fornecer aos usuários o caminho mais direto possível para os dados que eles querem e no formato que eles querem.
2.3 Ajuste do Projeto da Aplicação
Analistas de negócio e projetistas deveriam transformar metas de negócio em um projeto de sistema efetivo. Processos de negócio referem-se a uma aplicação particular dentro do sistema ou uma parte da aplicação. Um exemplo de projeto de processo é deixar alguns dados em cache. Deste modo você evita a recuperação da mesma informação várias vezes durante o dia.
2.4 Ajuste da Estrutura Lógica da Base de Dados
Depois da aplicação ter sido projetada, você pode planejar a estrutura lógica da base de dados. Um ajuste fino do projeto de índices, para garantir que não ocorra falta ou exagero de índices. Nesta fase você pode criar índices adicionais além da chave primária e estrangeira.
2.5 Ajuste das Operações de Base de Dados
Antes de ajustar o SGBD, esteja certo que sua aplicação utiliza todas as vantagens do SQL e das características do gerenciador para o processamento da aplicação. Utilize o otimizador do SGBD e o controle de ‘locks’. Entender o mecanismo de processamento da pesquisa no SGBD é importante para escrever comandos SQL efetivos.
2.6 Ajuste dos Caminhos de Acesso
Em bases de dados relacionais, a localização física dos dados não é tão importante como seu lugar lógico dentro do projeto da aplicação. Entretanto, a base de dados tem que encontrar os dados em ordem para retorná-lo para o usuário realizar a pesquisa. A chave para afinar o SQL é minimizar o caminho de pesquisa que a base de dados utiliza para achar o dado.
Garanta que exista acesso aos dados de modo eficiente. Considere o uso de ‘clusters’, hash ‘clusters’, índices B-tree, índices bitmap. Isto pode significar que você precise analisar novamente seu projeto depois de já ter sido construído.
2.7 Ajuste da Alocação de Memória
Alocação apropriada de recursos de memória para as estruturas do SGBD pode trazer efeitos positivos na performance. Alocação apropriada de recursos de memória melhoram a performance do cache, reduz o ‘parsing’ de comandos SQL e reduz a paginação.
2.8 Ajuste de I/O e Estrutura Física
I/O de disco tende a reduzir a performance de várias aplicações de software. O ajuste de I/O e estrutura física envolve:
*
Distribuir dados em discos diferentes para distribuir I/O e evitar contenção de disco;
*
Criar ‘extents’ grandes o suficiente para seus dados e evitar extensões dinâmicas das tabelas. Isto afeta a performance de alto volume de aplicações OLTP.
2.9 Ajuste da Contenção de Recursos
O processamento concorrente de vários usuários pode criar a contenção de recursos. A contenção faz com que os processos esperem até que os recursos sejam disponibilizados.
2.10 Ajuste das Plataformas Básicas
Conforme a versão do gerenciador para um determinado sistema operacional pode haver parâmetros diferentes de ajuste.
3. Como Aplicar a Metodologia
Nunca comece a tarefa de ‘tuning’ sem ter estabelecido objetivos claros. Você não pode ter sucesso sem uma definição do que é o sucesso. Mantenha seus objetivos em mente para considerar cada medida de ajuste, considere os benefícios de performance à luz de seus objetivos. Lembre que seus objetivos podem entrar em conflito. Por exemplo, para encontrar a melhor performance para um comando SQL, você pode sacrificar a performance de outro comando SQL concorrente em sua base de dados.
Os objetivos para ajuste de performance variam dependendo das necessidades da aplicação: aplicações de processamento online (OLTP), de suporte à decisão, processamento ‘batch’, aplicações distribuídas, etc. Se você está projetando ou mantendo uma aplicação, você deveria estabelecer objetivos de performance específicos para saber quando você deve realizar o ajuste. Você pode desperdiçar tempo ajustando seu sistema se você altera parâmetros de inicialização sem um objetivo específico.
Desenvolvedores de aplicações e DBA’s devem ser cuidadosos em estabelecer expectativas apropriadas de performance para os usuários.
Crie uma série mínima de testes que possam ser repetidos. Com um mínimo de testes estabelecido, com um ‘script’ para conduzir os testes e sumarizar e analisar os resultados, você pode testar várias hipóteses para ver o seu efeito.
Guarde os registros dos efeitos de cada mudança no ‘script’ de teste e automatize os testes.
Evite mudar alguma coisa no sistema por adivinhação. Você pode não ter pensado em todos os detalhes e afetar todo o ambiente. Você pode degradar a performance do ambiente a ponto de ter de reconstruí-lo a partir de ‘backups’.
Tente evitar preconceitos quando você tratar um problema de performance. Peça para os usuários descreverem o problema de performance. Não espere que os usuários saibam porque o problema existe.
Pare de realizar o ajuste quando os objetivos forem alcançados. Comunique aos usuários afetados pelo problema e os responsáveis pela aplicação.
4. Ajuste das Operações na Base de Dados
Todo acesso a dados relacionais pelos programas de aplicação é feito usando SQL. Revisões de SQL deveriam ser um componente necessário para análise de performance de aplicações em banco de dados antes e depois da implementação.
O principal culpado por problemas de performance é o SQL no código da aplicação. Segundo Craig Mullins [3][4][5] o consenso da indústria indica que 75% a 80% de todos os problemas de performance em banco de dados pode ser encontrado em códigos SQL ruins. Isto não significa que o SQL nas aplicações sejam ruins desde o início. De fato, uma aplicação pode ser 100% ajustada para acesso rápido quando ele é transferido para produção, mas durante o tempo ocorrem degradações de performance. Isto pode ocorrer por muitas razões tais como crescimento da base de dados, novos caminhos de acesso, mudanças no negócio, etc.
Foque seus esforços de ajuste em comandos onde os benefícios de ajuste excedem o custo do ajuste. Em complementação a políticas e procedimentos para análise e revisão de SQL podem ser usadas ferramentas automatizadas para minimizar o volume de códigos SQL ruins. Use ferramentas tais como TKPROF, SQL Trace Facility e outras para encontrar o problema. Encontre os comandos que consomem mais recursos e/ou são executados mais freqüentemente. Não adianta ajustar comandos SQL para projetos ineficientes da aplicação.
O SQL é projetado para que o programador especifique que dados são necessários e não como recuperá-los. O otimizador do SGBD se encarrega dessa parte. Otimizadores do SGBD geralmente fazem uma boa escolha do caminho de acesso mais eficiente, mas não sempre. É necessário um método para monitorar e ajustar as operações na base de dados. O SQL é o coração das aplicações modernas com bancos de dados. Se forem mal codificados e concebidos, a performance da aplicação sofrerá e os processos do negócio sofrerão impactos negativamente.
4.1 Abordagens para ajuste de comandos SQL
4.1.1 Reestruture os índices
Reestruturação de índices é um bom ponto de começo, porque ela tem mais impacto na aplicação que a reestruturação do comando ou dos dados.
Analise a eficiência dos índices usando Explain Plan. Veja que índices são usados para pesquisas comuns e exclua qualquer um que não esteja sendo usado. Muitos índices em uma tabela podem causar uma sobrecarga, pois todos os índices precisam ser atualizados na atualização da tabela.
Remova índices não seletivos, crie índices para caminhos de acesso com performance crítica e considere outros tipos de índices.
4.1.2 Reestruture o comando SQL
Depois de reestruturar os índices, você pode tentar reestruturar os comandos SQL. Escrever novamente um comando SQL ineficiente é mais fácil do que repará-lo. Se você entender a finalidade do comando, você pode rapidamente escrever um novo comando que atenda aos requisitos.
O SQL é uma linguagem flexível. Comandos SQL podem ser formulados de várias maneiras diferentes com a mesma funcionalidade. A performance destas opções podem flutuar grandemente, mas os dados retornados para a aplicação podem ser equivalentes. Por esta razão, é imperativo que a melhor opção seja usada para garantir uma boa performance. Uma revisão de SQL conduzida por analistas com experiência em performance pode capturar estes tipos de potenciais problemas de performance. Use o resultado do comando Explain Plan para comparar os planos de execução e custo dos comandos e determinar qual é mais eficiente.
O principal objetivo do ajuste de SQL é evitar realizar trabalho desnecessário para acessar linhas que não afetarão o resultado. Evite ler uma tabela inteira se é mais eficiente obter as linhas desejadas através de um índice. Evite usar um índice que traga mais linhas que um outro.
Quando múltiplas tabelas são acessadas em um comando SQL as tabelas podem ser combinadas em qualquer ordem e ainda retornarem o resultado correto. A performance, entretanto, pode variar grandemente dependendo do volume dos dados nas tabelas, da natureza do pedido e dos índices disponíveis para a tabela. A ordem de um Join pode ter um efeito significativo de performance. Escolha uma ordem do Join de modo a juntar menos linhas nas tabelas posteriores da ordem do Join.
Torne-se familiar com algumas formas de monitoração de comandos SQL da Shared Pool. Conhecendo a que o código no pool se assemelha ajudará a adotar convenções de codificação. Usando convenções similares para comandos que já estão no pool, você poderá reutilizar o que já está lá. Desenvolva padrões de codificação para comandos SQL em sua instalação. Decida questões tais como palavras-chave, alinhamento de comandos e aliás de objetos.
Torne-se influente com o uso do otimizador baseado em custo. Experimente, analise os resultados e incorpore-o em suas aplicações onde eles podem se beneficiar mais.
Minimize o tempo de recursos bloqueados com o comando ‘commit’ logo após as alterações do banco.
Use valores de coluna sem transformação. Não use funções SQL em cláusulas de predicado ou cláusulas ‘where’ pois eles deixarão de utilizar índice.
Evite misturar tipos de dados em expressões e tome cuidado com conversões implícitas de tipo. Qualquer expressão usando uma função com a coluna como seu argumento, o otimizador ignorará a possibilidade de usar o índice daquela coluna. Podem ocorrer erros na conversão de dados.
Escreva comandos SQL separados para valores específicos. SQL não é uma linguagem procedural. Não é uma boa idéia usar um pedaço de SQL para fazer diferentes coisas. Geralmente o resultado é pior que o resultado para cada tarefa.
Cuidado ao usar IN com uma lista de valores. Isto pode indicar a falta de uma entidade.
Não recicle 'views'. As vezes você estará acessando a 'view' desnecessariamente e seria mais rápido acessar a tabela original.
4.1.3 Modifique ou desabilite ‘triggers’
A utilização de ‘triggers’ consome recursos do sistema. Se você usa muitos ‘triggers’, você pode afetar negativamente a performance e você pode precisar modificá-lo ou desabilitá-lo.
4.1.4 Reestruture o Dado
Depois de reestruturar os índices e o comando, você pode considerar a reestruturação do dado. Introduza valores derivados. Evite cláusula ‘Group By’ em códigos com respostas críticas. Implemente entidades que faltam e tabelas de interseção. Reduza a carga da rede. Migre, replique ou particione os dados.
5. Conclusão
O administrador de banco de dados (DBA) pode ser um parceiro estratégico no desenvolvimento e manutenção de aplicações:
* gerenciando pró-ativamente os sistemas. Identificando problemas potenciais antes de eles ocorrerem, prevenindo quedas do sistema e perda de dados;
Utilizamos cookies para melhorar a sua experiência neste site. Ao fechar esta mensagem sem modificar as definições do seu navegador, você concorda com a utilização deles. Saiba mais sobre cookies e nossa política de privacidade.