Duas descrições: uma já do tempo do onça (Dbase, lembram disso?), e outra, bem mais moderna, do SYBASE. Diversão garantida.
XBASE - características
O dbase foi o primeiro produto de banco de dados para uso em microcomputadores. Lançado em 1980 como Dbase2 (nunca existiu um Dbase1), tinha limitações que hoje fariam corar o mais circunspecto analista de sistemas, mas, na época, foi uma revolução. De 82 a 87 reinou soberano, e acabou criando uma genealogia de produtos e metodologias (Dbase2, 3, 3plus, 4, 5, Visualdbase 7, FoxPro, FoxBase, Paradox, Clipper, só para ficar nos mais conhecidos).
Sua importância hoje reside no fato de que 100% dos produtos que interagem com algum tipo de banco de dados em microcomputadores aceitam o padrão Dbase. Assim, por exemplo, o AutoCad aceita dados em formato Dbase. O MSWord aceita dados para mala direta no formato Dbase e assim por diante.
Também é importante estudá-lo pela simplicidade do esquema e pelo fato de que funciona, e bem. Finalmente, por questões de propriedade de marca, o nome Dbase foi abandonado (já que o nome -- mas não os formatos -- é registrado pelos proprietários, originalmente a Ashton Tate e depois a Borland) e em seu lugar usa-se o termo Xbase.
Um banco de dados DBASE é um conjunto de diversos arquivos, cujos principais são:
Tipo de arquivo
Conteúdo
DBF
Data Base File: o arquivo que contém os dados. Tem registros de tamanho fixo, e as inclusões sempre se dão ao final do arquivo. Exclusões mantêm o registro no seu lugar, até que ocorra um PACK. Atualizações se dão no mesmo lugar.
NDX
Index File: O arquivo organizado na forma de uma árvore B+. Os apontadores para o número do registro (no DBF equivalente) só existem nas folhas.
DBT
Data Base Text: Arquivo que contém os campos MEMORANDO que porventura sejam definidos no DBF. Lá fica apenas um apontador de 10 bytes para o endereço do memorando equivalente que está no arquivo DBT.
Data Base Text: Arquivo que contém os campos MEMORANDO que porventura sejam definidos no DBF. Lá fica apenas um apontador de 10 bytes para o endereço do memorando equivalente que está no arquivo DBT.
O Dbase armazena os dados brutos em arquivos cuja extensão é DBF (data base file). Cada registro que é incluído o é no fim do arquivo e ele é numerado seqüencialmente no instante em que entra no arquivo.
No começo do arquivo, vem o lay-out dos dados. Seria o header, com o seguinte formato:
Cada campo, por sua vez, está assim descrito (ocupando 32 bytes cada):
Os tipos aceitáveis são:
Alfanumérico com tamanho de até 256 bytes, numérico podendo ou não ter decimais, lógico, data e memorando.
Notas: algumas assinaturas importantes: x'02' é Foxbase, h'03' é Dbase sem arquivos memo, x'30' é VisualFoxPro, x'83' é Dbase com campos memo...
O tamanho de cada registro é a soma dos tamanhos dos campos do arquivo, mais 1 (que é usado como sinalizador de exclusão).
As páginas em Dbase ocupam 512 bytes.
Finalmente, depois deste header, vêm os dados, gravados seqüencialmente, um depois do outro.
Estrutura dos Índices
Os índices em Dbase são guardados em arquivos separados, o que -- como tudo na vida -- tem vantagens e desvantagens. Vantagem: por definição, índices são descartáveis, e não precisam ser guardados. Desvantagem: eles podem ser ignorados em operações de inclusão/exclusão, o que diminui a confiabilidade deles.
Os índices são criados através de um comando Dbase que recebe os parâmetros que ajudarão a montar o índice; lê o arquivo de dados e constrói o índice. Ele usa uma estrutura de árvore B+, que vem a ser uma árvore B, na qual as informações de chave estão apenas nas folhas, o que permite a leitura "seqüencial" do arquivo de dados em qualquer ordem determinada por um arquivo de índices.
O arquivo NDX tem um header que contém:
O número da página inicial do índice;
O número total de páginas do índice;
O comprimento da chave que construiu este índice;
O número de chaves por página;
O tipo da chave (numérica ou alfa);
Tamanho das entradas de índice (4 para a próxima entrada + 4 para o número do registro no arquivo DBF + expressão da chave arredondada para múltiplo de 4);
A string que define a chave deste arquivo de índices.
Cada uma das demais páginas tem um campo de 4 bytes com o número de entradas válidas na página corrente e, a partir do byte 4, um array de entradas de chaves. Cada elemento deste array é um apontador para o nível inferior, o número do registro no arquivo DBF e o valor da chave.
SYBASE - Características
O SYBASE usa árvores B para indexar as tabelas. Existem 2 tipos de árvores B: as granuladas e as não granuladas (clustered). As granuladas são árvores esparsas (nem todo registro de dados tem entrada nos índices) nas quais os registros (na tabela original) são mantidos em ordem dos valores de índice e apenas o primeiro registro em cada página de dados tem uma entrada de índice. Árvores não granuladas são densas e cada um dos registros da tabela tem 1 entrada de índice.
Uma tabela SYBASE com índice granulado exige que seus elementos sejam mantidos em ordem dentro da tabela. Assim, inclusões podem se dar em qualquer página, a depender do conteúdo do campo de índice. Tabelas SYBASE, que têm apenas índices não granulados, fazem as inclusões de novos elementos sempre ao final das tabelas (na última página).
Tabelas SYBASE podem ter apenas 1 índice granulado, mas podem ter até 250 índices não granulados.
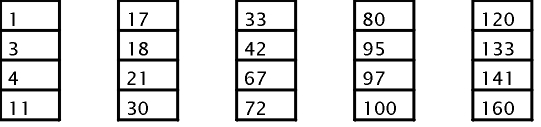
Na criação de um índice granulado, os dados da tabela devem estar colocados nas páginas em ordem. Por exemplo: seja criar uma tabela com os campos 1, 120, 33, 95, 4, 67, 160, 72, 141, 80, 11, 21, 133, 30, 42, 100, 97, 18, 17 e 3.
Páginas de dados
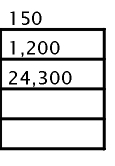
Apenas o primeiro registro da tabela será indexado, ou neste caso: 1, 17, 33, 80 e 120. Supondo que as páginas de índices comportem apenas 4 entradas, seriam necessárias 2:
Sendo, uma árvore B, haveria uma nova entrada, acima desta contendo:
O nodo raiz se encontra num arquivo chamado sysindexes.
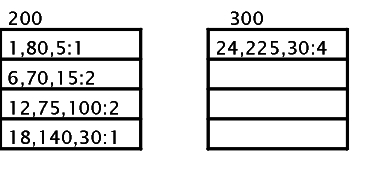
Cada entrada no índice de um índice granulado (esparso) é um apontador para página. Um apontador de página é composto por 5 bytes, assim uma entrada do índice é um valor de chave e um apontador de página.
Páginas de dados
Índices Não Granulados (denso)
Nestes índices, todos os componentes da área de dados fazem parte do índice, mas os dados não precisam estar ordenados.
Perceba-se que há uma diferença grande na quantidade de acessos quando se busca um intervalo de registros e estes estão ordenados por índices granulados (esparsos) ou não granulados (densos).
Eis como ficaria:
nodo raiz
nível intermediário
folhas
Páginas de dados
Cada entrada de índice em Sybase pode ser composta por até 16 campos e ter até 256 bytes. Estes campos não precisam estar contíguos. Só não podem ser partes de campos e resultados de cálculos.
Páginas
O tamanho da página varia, mas o tamanho mais comum é 2K. Existem 5 tipos de páginas em Sybase, a saber:
Páginas de Dados: contêm registros de dados ou registros de log. Ambos são estruturalmente diferentes, mas são construídos do mesmo jeito.
Páginas de índices: contêm registros de índice.
Páginas de texto ou imagem: contêm BLOBS.
Páginas de alocação: contêm estruturas de dados usadas para gerenciar o processo de alocação de páginas.
Páginas de Estatísticas: contêm estatística de distribuição e uso para os índices.
Página de Dados
Se os registros têm tamanho fixo, não haverá tabela de deslocamento na página e o endereço de cada registro é obtido mediante simples cálculo. Neste caso, o tamanho do registro (fixo) é guardado no campo TAMANHO MÍNIMO DE REGISTRO do header.
O header da página é um conjunto de 32 bytes contendo (entre outros): número lógico da página, anterior e próxima página lógica, identificação do objeto ao qual esta página pertence, primeira entrada de registro disponível nesta página, deslocamento do espaço livre, tamanho mínimo do registro.
Depois vem a área de registros, que contém um número inteiro de slots para guardar registros. Um registro não atravessa limites de páginas.
Tabela de deslocamento: Um conjunto de deslocamentos desde o início da página dando o início de cada um dos registros. Este conjunto cresce do fim da página para o início e só existe quando o tamanho do registro é variável.
Cada registro na página recebe um número de registro. É um campo de 1 byte e assim restringe-se o número de registros em uma página a 256. O número do registro usado nos índices não granulados (densos) é uma combinação do número da página com o número do registro na página.
O registro pode ocupar a página inteira (2048-32=2016). Não há tamanho mínimo para o registro, mas só pode haver 256 registros na página.
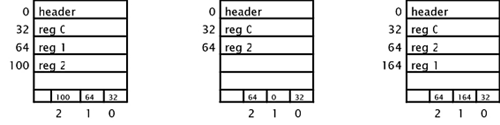
Um Registro em SYBASE
Seja por exemplo, um registro assim definido
create tabela1 (a int, b char(20))
que gerará um layout como segue:
Já a tabela
create tabela2 (a int, b varchar(20), c char(30), d varchar(10))
gerará a o seguinte lay-out:
Note que os dados de tamanho variável são todos juntados ao final do registro. Tem-se:
2=número de campos de tamanho variável
40=número deste registro dentro desta página campos fixos
57=tamanho deste registro campos de tamanho variável
38=o campo B começa na posição 38
48=o campo D começa na posição 48
A busca dentro da página é feita por pesquisa binária. Quando o tamanho do registro é fixo, a coisa é trivial. Quando o tamanho é variável, há uma tabela de deslocamento dos registros no fim da página.
Eis como ficaria uma página de dados com registros de tamanho variável:
A entrada na tabela de deslocamento contém o endereço real do registro na área de dados que, lembrando, começa no &32. Note que a tabela de deslocamento é ideal para uma pesquisa binária dentro da página.
O deslocamento 0 no registro 1 indica que o mesmo foi excluído. A próxima inclusão nesta página reaproveitará o número 1 presentemente livre, ainda que o registro seja gravado fisicamente ao final da página.
Quando os registros são excluídos, os que sobram são reagrupados no início da página de maneira a manter um único bloco de espaço livre ao final da página.
Veja a seguir um exemplo de uma exclusão seguido de inclusão em um arquivo: